

Vivienne Tam
Vivienne Tam是一个定位高端的时尚品牌,由华裔设计师Vivienne Tam(谭燕玉)于1994年在美国纽约创立
PubMedQA 数据集介绍
PubMedQA 是一个专门设计用于支持开发和评估能够在生物医学文献中找到答案的问答系统的高质量数据集。它由PubMed文献库中的数据构建而成,这些文献库是全球最大的生物医学文献数据库之一。以下是关于 PubMedQA 数据集的详细介绍:
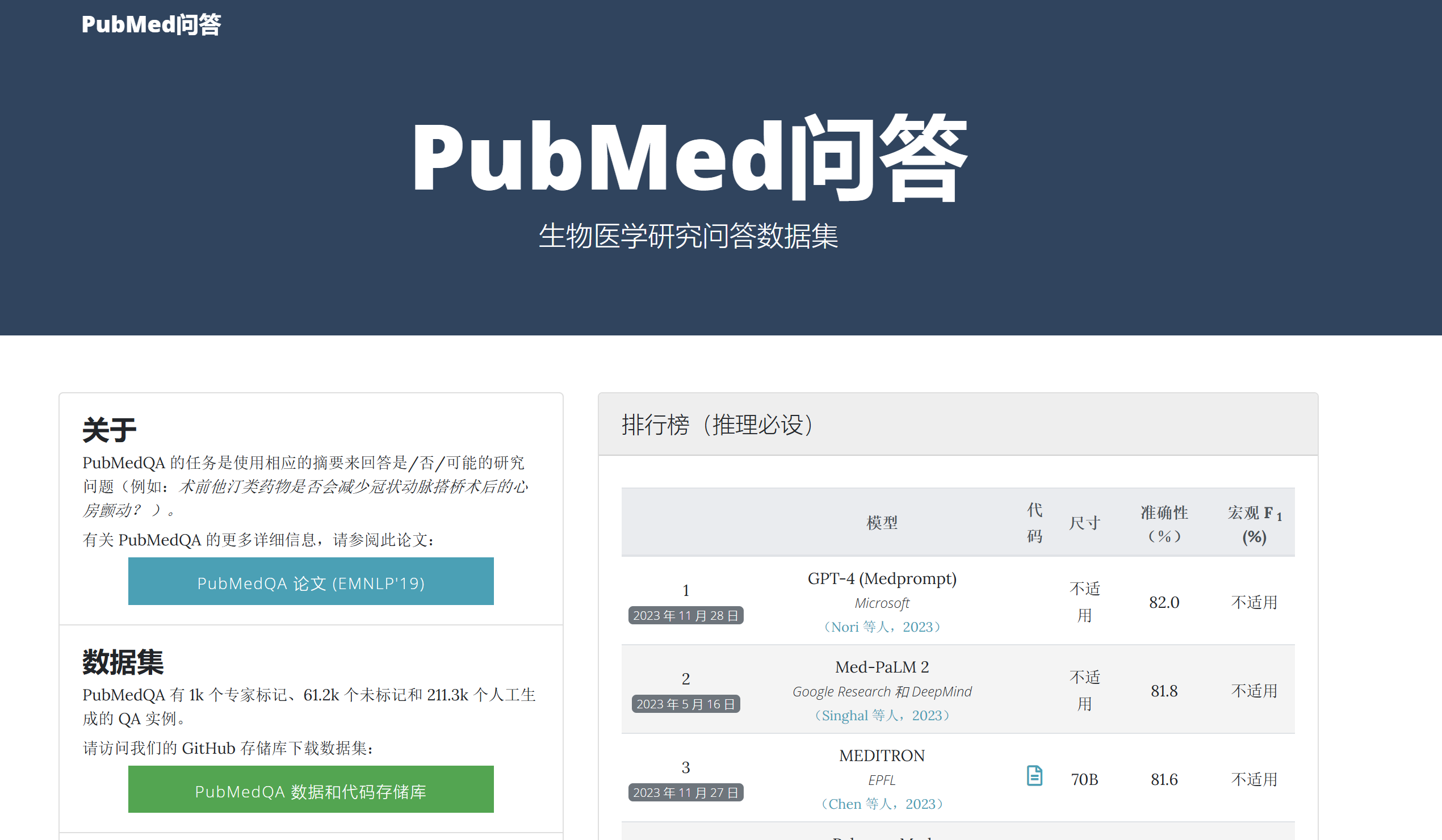
来源可靠:
问题类型丰富:
答案格式明确:
标签指示答案可获取性:
每个PubMedQA实例都包含以下四个主要组成部分:
自然语言问题(Question):
问题相关的文献引用(Citation):
答案摘录(Evidence):
标签(Label):
PubMedQA 数据集包含以下规模的实例:
此外,数据集还提供了一个包含500个测试实例的是/否/也许答案的测试集(test_ground_truth.json)。
PubMedQA 数据集旨在为研究者们提供一个统一的平台来测试和比较不同的问答系统技术。通过使用这个数据集,研究者可以开发出更准确、更高效地从大量生物医学文献中提取关键信息的算法。这些算法最终能够帮助医疗保健专业人士快速找到关于特定疾病、治疗方法或其他生物医学主题的相关文献信息。
促进生物医学问答系统的发展:
提高信息提取效率:
评估模型性能:
PubMedQA 数据集可以通过相关学术资源平台或研究机构提供的链接进行下载。使用数据集时,请遵循相应的使用协议和规定,确保数据的合法合规使用。
PubMedQA 数据集是一个专门为生物医学问答系统设计的高质量数据集,它通过提供丰富的自然语言问题、文献引用和答案摘录,帮助研究者构建和验证能够准确处理和回答生物医学问题的算法。这个数据集对于推动生物医学问答系统的发展具有重要意义。






