

柏林工业大学
柏林工业大学(Technische Universität Berlin,简称 TU Berlin) 是德国最著名的工科大学之一,以工程技术、建筑与城市规划、计算机科学、人工智能、能源与环境、交通系统、工业设计、经济与管理、跨学科研究见长,是欧洲理工教育与科技创新的核心节点高校之一。
MMLU Dataset旨在通过仅在零样本和少样本设置中评估模型来衡量预训练期间获得的知识。这使得基准测试更具挑战性,并且更类似于人类评估知识的方式。该基准涵盖了STEM(科学、技术、工程和数学)、人文、社会科学等领域的57个学科,难度从初级到高级专业水平不等,既考验世界知识,也考验解决问题的能力。
MMLU Dataset(大规模多任务语言理解数据集)是一个用于评估语言模型在多任务上的表现的基准测试数据集。以下是关于MMLU Dataset的详细介绍:
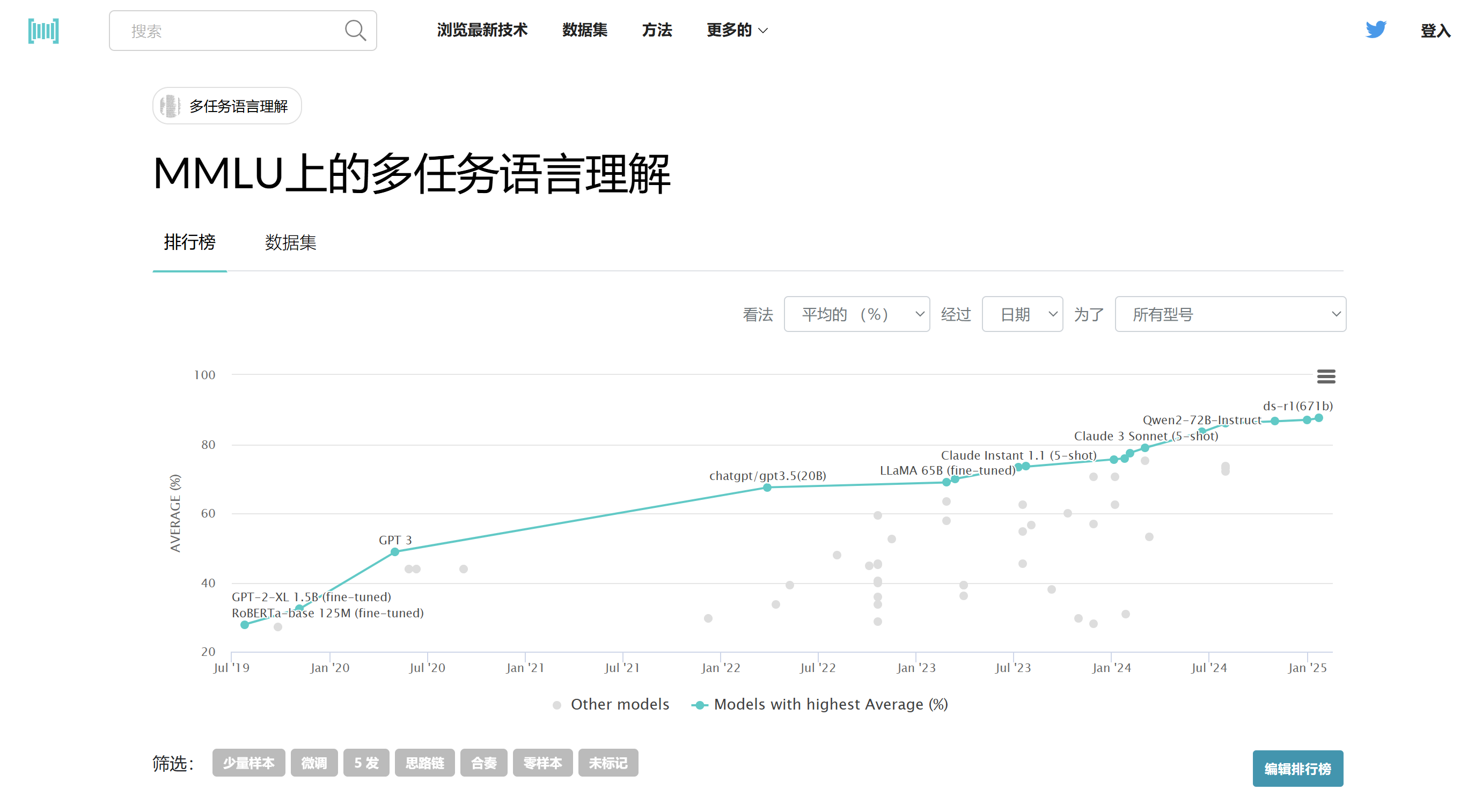
MMLU Dataset旨在通过仅在零样本和少样本设置中评估模型来衡量预训练期间获得的知识。这使得基准测试更具挑战性,并且更类似于人类评估知识的方式。该基准涵盖了STEM(科学、技术、工程和数学)、人文、社会科学等领域的57个学科,难度从初级到高级专业水平不等,既考验世界知识,也考验解决问题的能力。
MMLU Dataset包含开发集、验证集和测试集。少样本开发集每个科目有5个问题,用于少样本学习以启动模型;验证集可用于选择超参数,由1540个问题组成;测试集有14079个问题,是评估问题的主要来源。
MMLU Dataset广泛应用于评估各种语言模型在多任务语言理解方面的能力。通过在该数据集上的表现,可以识别模型的盲点和不足,推动模型在多任务语言理解方面的进一步改进和发展。
使用MMLU Dataset评估一个预训练的语言模型时,可以按照以下步骤进行:
值得注意的是,MMLU Dataset中有6个领域与医学知识相关,包括解剖学、临床知识、专业医学、遗传学、大学医学和大学生物学。这使得MMLU Dataset在医学领域的自然语言处理研究中也具有重要的应用价值。
MMLU Dataset是一个全面且具有挑战性的基准测试数据集,用于评估语言模型在多任务语言理解方面的能力。通过在该数据集上的表现,可以识别模型的盲点和不足,推动模型在多任务语言理解方面的进一步改进和发展。对于致力于语言模型研究和开发的研究人员来说,MMLU Dataset是一个宝贵的资源。






